
Philippe Rigollet
Philippe Rigollet is the Cecil and Ida Green Distinguished Professor of Mathematics. His research interests span a wide range of mathematical topics, particularly those emerging from the fields of statistics, data science, and artificial intelligence. Currently, he focuses on statistical optimal transport and the mathematical foundations of Transformers.
Affiliations

Academic Positions
Professor
MIT, Mathematics, 2020 -
Associate Professor
MIT, Mathematics, 2016 - 20
Assistant Professor
MIT, Mathematics, 2015 - 16
Assistant Professor
Princeton, ORFE, 2008 - 14
Postdoc
Georgia Tech, Mathematics, 2007 - 08
Education & Training
Ph.D. in Mathematics
Univ. of Paris 6 (now Sorbonne Univ.) - 2006
M. Sc. in Statistics & Actuarial Science
ISUP - 2003
B. Sc. in Applied Mathematics
Univ. of Paris 6 (now Sorbonne Univ.) - 2002
Selected Awards
2026
2023
2021
2021
2013
2011
Featured Work

Transformers and Self-Attention dynamics
ArXiv [2512.01868][2312.10794]
Our group recently initiated a line of work where we aim to develop a mathematical perspective on transformers by viewing them as interacting particle systems. As in neuralODEs, we view (self-attention) as velocity fields that evolve particles (token) towards a useful embedding. Our initial work has largely focused on shedding light on the clustering behavior of this system of interacting particles. Even in a very stylized model, many intriguiging mathematical questions arise.

Wasserstein gradient flows
YouTube EBA0NyY4Myc
This talk gives an overview of our recent work on applications of Wasserstein gradient flows to problems arising in statistics and machine learning. The Wasserstein geometry and its extensions (notably Wasserstein-Fisher-Rao) provide a toolbox to develop particle-based optimization algorithms over probability measures. These ideas have been implememented in several examples such as variational inference and nonparametric maximum likelihood estimation.
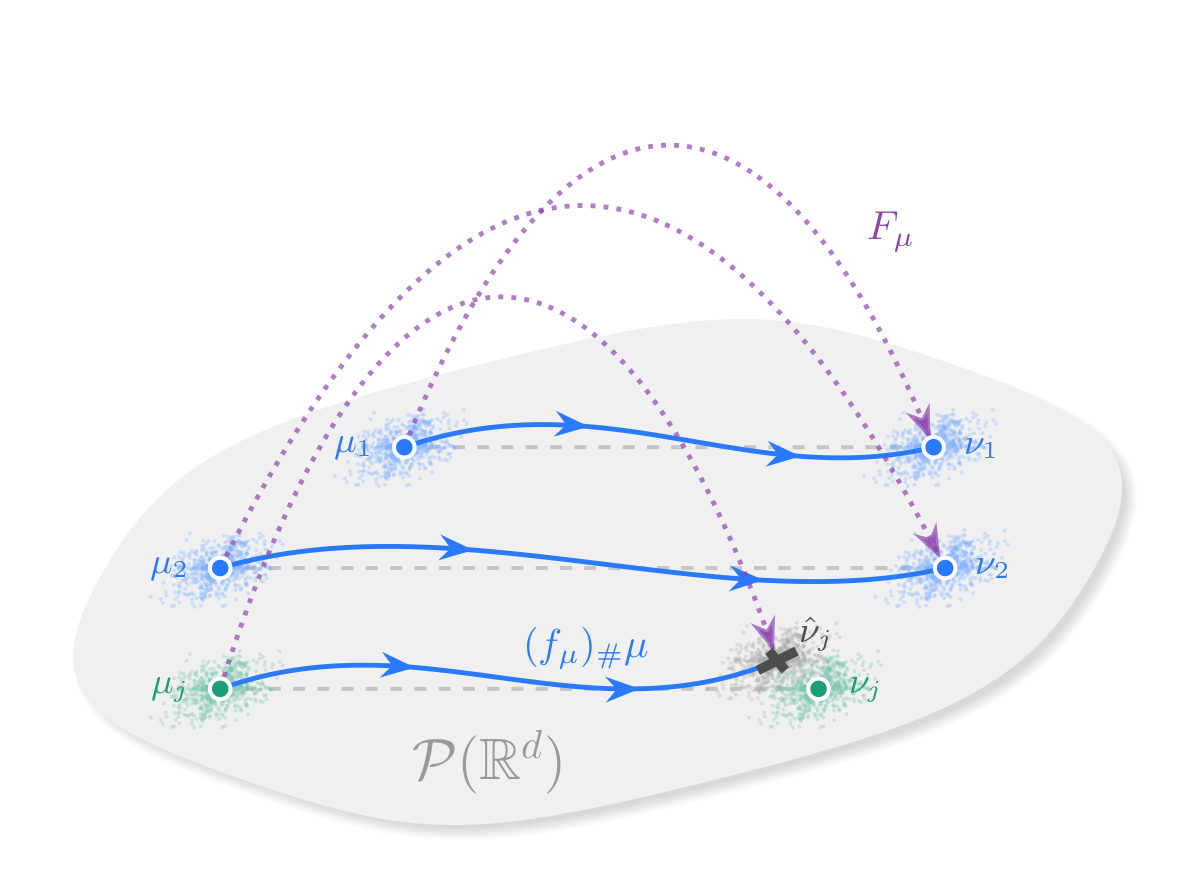
Biological applications
ArXiv 2605.28075
Our group is applying transformers to biological data by treating entire cell populations as probability measures. This measure-to-measure perspective learns how distributions evolve under interventions, using transformers as static maps or dynamic velocity fields to predict treatment response in settings such as patient-derived organoids.
Research Group







Alumni
Openings
Interested in joining our group?
I receive many inquiries from highly qualified candidates, so I am not able to respond individually to emails asking whether I will be taking Ph.D. students or postdocs in the fall.
In principle, I am always evaluating complete applications in my areas of expertise, but decisions are made through the appropriate departmental process, and I cannot assess individual cases before seeing recommendation letters, transcripts, and research statements. The best first step is to identify the most appropriate position and apply; once you have applied, there is no need to contact me separately, but please flag me as a reader in your application.
I do not host interns.
Current Funding
NSF DMS-2509011
Theoretical Foundations of Efficient and Scalable Graph Learning
Contact
The best way to contact me is via email